Mining and Modeling Text – MiMoText
Interdisciplinary Applications, Informational Development, Legal Perspectives
Project Management: Prof Dr Christof Schöch (Universität Trier - Computerlinguistik & Digital HumanitiesUniversität Trier - Trier Center for Digital Humanities (TCDH)) · Universität Trier - Trier Center for Digital Humanities (TCDH)
Project Participants: Universität Trier - Fachbereich II (Sprach-, Literatur- und Medienwissenschaften) · Universität Trier – Fachbereich IV (Informatikwissenschaften) · Universität Trier – Fachbereich V (Rechtswissenschaft) · Fachinformationsdienst (FID) Romanistik · Universität Trier - Universitätsbibliothek Trier
Sponsors: Forschungsinitiative des Landes Rheinland-Pfalz
Running time: -
Contact person (TCDH): Prof Dr Christof Schöch; Prof Dr Claudine Moulin; Dr Joëlle Weis
References:
Schöch, Christof, Maria Hinzmann, Julia Röttgermann, Katharina Dietz, und Anne Klee. 2022. „Smart Modelling for Literary History“. International Journal of Humanities and Arts Computing (IJHAC) 16 (1): 78–93. https://doi.org/10.3366/ijhac.2022.0278.
Research Area: Software Systems and Research Infrastructure, Digital Literary and Cultural Studies
Keywords: Quantitative Analysis, Literary History, Linked Open Data, 18th century
Technologies:
Website of the Project: Mining and Modeling Text
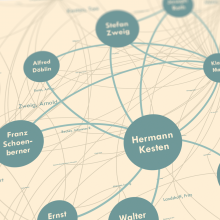
The acquisition of knowledge from large amounts of text and data which can no longer be handled by individuals is becoming increasingly important due to the possibilities of digitization. For the humanities, this means in particular that digital full texts and rich metadata must not only be available, but must also be available in a form that promotes knowledge in the humanities.
The aim of the MiMoText project is therefore to establish an information network for the humanities that is fed from various sources and is not only freely available and linkable to other knowledge resources on the Semantic Web, but also offers new and efficient ways of accessing specialist academic information by providing it as linked open data. The focus is on sources on the history of the French novel from 1751 to 1800, with access to some existing full-text digital copies (e.g. from Gallica).
Bibliographic directories, specialist literature and primary texts serve as sources of information. From these, metadata, concrete text properties and descriptive or evaluative statements about relevant entities are extracted for example authors and works. For this purpose, quantitative methods for automatic text analysis as well as for the extraction and modelling of data from extensive text collections must be further and partly newly developed. After that, the information is converted into a Linked Open Data format and can be linked to each other and to the outside world. From the start of the project, the legal framework will also be analyzed in order to ensure that the knowledge network is set up and made available in accordance with copyright and data protection laws.
Website: https://mimotext.uni-trier.de/
Tutorial: https://docs.mimotext.uni-trier.de
SPARQL endpoint: https://query.mimotext.uni-trier.de
MiMoTextBase: https://data.mimotext.uni-trier.de
GitHub: https://github.com/MiMoText/
Project spokesperson: schoech uni-trier.de (Prof. Dr. Christof Schöch)
uni-trier.de (Prof. Dr. Christof Schöch)
Deputy speaker: moulinuni-trier.de (Prof. Dr. Claudine Moulin)
Team TCDH
Dr Joëlle Weis
E-mail: weisuni-trier [dot] de
Phone: +49 651 201-3017
Dr Maria Hinzmann
E-mail: hinzmannmuni-trier [dot] de
Phone: +49 651 201-3101
Dr Matthias Bremm
E-mail: bremmuni-trier [dot] de
Phone: +49 651 201-4733
Dr. Anne Klee
E-mail: kleeuni-trier [dot] de
Phone: +49 651 201-3120
Johanna Konstanciak
E-mail: konstanciakuni-trier [dot] de
Phone: +49 651 201-4097
Julia Röttgermann
E-mail: roettgeruni-trier [dot] de
Phone: +49 651 201-1165
Prof Dr Christof Schöch
E-mail: schoechuni-trier [dot] de
Phone: +49 651 201-3264
Prof Dr Claudine Moulin
E-mail: moulinuni-trier [dot] de
Phone: +49 651 201-2305
Tatiana Bessonova
E-mail: s2tabessuni-trier [dot] de
Phone: +49 651 201-3365