SeNeReKo
Semantic-Social Network Analysis as an Instrument for Researching Religious Contacts

Project Management: Ruhr-Universität Bochum – Centrum für Religionswissenschaftliche Studien (CERES) · Universität Trier - Trier Center for Digital Humanities (TCDH)
Sponsors: BMFTR – Bundesministerium für Forschung, Technologie und Raumfahrt
Running time: -
Contact person (TCDH): Dr Thomas Burch
Research Area: Software Systems and Research Infrastructure, Digital Literary and Cultural Studies
Keywords: Digital Technologies and Tools
Website of the Project: SeNeReKo
The digitization of historical source material has created a number of new possibilities in terms of storage and processing. However, the resulting potential for analysis is far from being exhausted. SeNeReKo therefore saw itself as a field of experimentation for the development and application of new processes between the humanities and computer science.
The project work was not only able to provide content-related answers to open research questions, but also enabled insights into the interdisciplinary cooperation and offered best practice examples for future projects.
The SeNeReKo project pursued two questions:
- What information about interreligious exchange processes can be obtained from historical source material?
- How can current data analysis methods help?
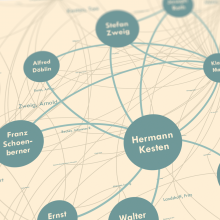
The development of the necessary technical procedures was the responsibility of the TCDH. The aim of the Trier sub-project was to provide a virtual research platform that supports the entire work process from recording the digitized texts through their analysis to the visualization of the results. Existing tools were used and adapted, and new processes and methods were developed: FuD served as the integrative basis of the platform, which was initially expanded to include components for (semi) automatic text analysis as well as for evaluating and visualizing the work results. For the text analysis, a bundle of procedures from the field of text mining was provided, which should enable the processor to filter out structures of meaning from weakly structured texts and thus to develop core information. A particular challenge was the adaptation and new development of text mining methods for the languages Pali and Egyptian. The automatic procedures were also supported by a module for manual evaluation and follow-up control of the calculated results. A graph database, which was integrated into FuD via a suitable interface, enabled the efficient storage and evaluation of the analysis results. The graph database could be connected to a network visualization component via a further interface in order to enable an easy and obvious interpretation of the semantic relations.
All analysis methods and software components developed in the course of the project have a generic character and were made available for re-use after their development for future research. In addition, the desired results should not only strengthen the interdisciplinary cooperation between the humanities and computer science in the field of eHumanities, but also stimulate basic research in philologies and find their way into university teaching.