
Pathbreaking
Further legal guidance published
14.09.2022 | General, Project News

Photo by Aaron Burden on Unsplash
As part of the legal support provided to the project by the IRDT, legal topics are identified that arise in the project context of "Mining and Modeling Text (MiMoText)" as examples. These will be abstracted in the form of practical guidelines, which will be as practical as possible. The written guidelines will be published in the PAPERSERIES of the IRDT.
From the ongoing project work, jurisprudential questions relevant to the Digital Humanities are emerging. Corresponding problem areas are being worked on in order to be able to offer suggestions for the Digital Humanities beyond the project context with these guidelines, but also, for example, for the edition sciences. The goal is to present legally relevant problem areas in a general and interdisciplinary way.
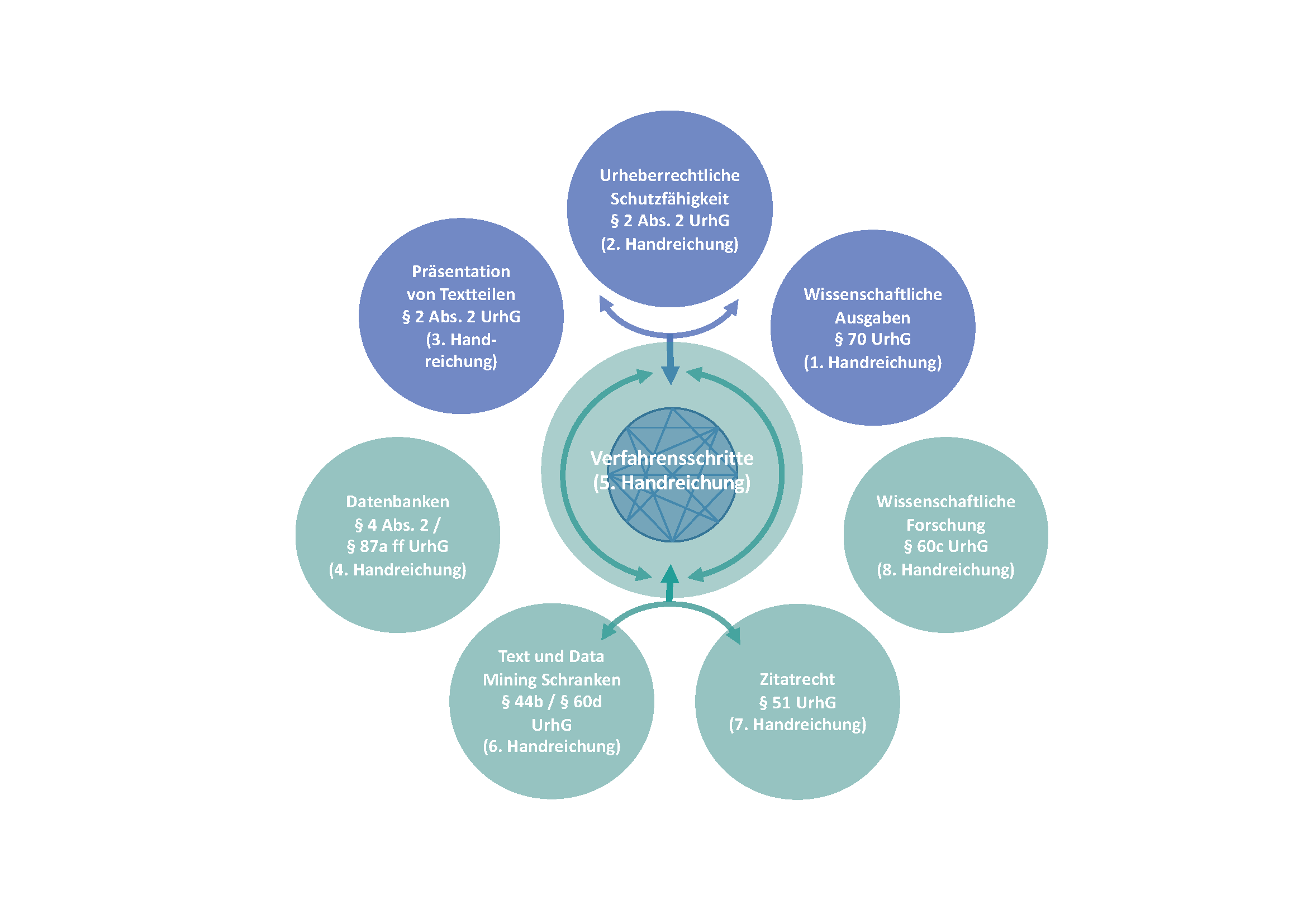
The legal guidance No. 4: „Datenbanken als Quelle oder Ergebnis von Textanalysen – Datenbankwerkschutz und das Leistungsschutzrecht des Datenbankherstellers“ looks at databases. These gain importance in text and data mining analyses in two ways. The extraction of materials from databases may be subject to copyright restrictions. However, they can also be the result of the text and data mining process, whereupon they are the starting point for copyright protection. On the one hand, the handout presents the requirements for this protection. This is important for the question of when texts may be extracted or reused. On the other hand, the handout clarifies the question of the ownership of rights, as far as a database is the result of a text and data mining process.
The digital humanities make use of (partially) automated process steps. Handout No. 5: „Verfahrensschritte bei dem Einsatz von Text und Data Mining-Verfahren in den Geisteswissenschaften“ describes these. The individual procedural steps are the starting point for copyright evaluation. Copyright law usually links to human actions, so that an exciting legal perspective arises when analyzing the text and data mining steps.
The respective guidelines always have the copyright restrictions in mind, but also show a framework to what extent parts of the works and ancillary copyrights can be freely used. For this, Guidance No. 6: „Die Text und Data Mining-Schranken und ihr Rahmen für Textanalysen in den Digital Humanities“ presents the extent to which the text and data mining barriers provide a framework for extracting information from protected texts, collecting sources, and preserving the results as well as the source texts. The citation barrier can also be used as evidence for presenting portions of text. Handout No. 7: „Das Zitat und dessen Rahmen für Belege bei Textanalysen“ discusses the extent to which the citation barrier provides a framework for intellectual engagement with copyrighted texts and portions of texts.
The science barrier regulates the free use of intellectual property for teaching, science and research. New legislation has changed the legal situation for scientists in dealing with copyright-relevant data and products. In preparation is the document No. 8, which will deal with „Die Wissenschaftsschranke“. In other words, the extent to which parts of a copyrighted object can be reproduced for the purposes of non-commercial scientific research.
Topics: Digital Literary and Cultural Studies, Data Retrieval, Science Communication, Computational Literary Studies
Projects: Mining and Modeling Text – MiMoText